What is Minimum Viable (Data) Product?
This post gives a personal insight into what Minimum Viable Product means for Machine Learning and the importance of starting small and iterating.
By Dat Tran, Idealo.

A couple of months ago I left Pivotal to join idealo.de (the leading price comparison website in Europe and one of the largest portals in the German e-commerce market) to help them integrating machine learning (ML) into their products. Besides the usual tasks like building out the data science team, setting up the infrastructure and many more administrative stuff, I had to define the ML powered product roadmap. And associated with this was also the definition of a Minimum Viable Product (MVP) for machine learning products. The question I often face though, here at idealo and actually also back at my time at Pivotal, is what actually a good MVP means? In this article, I will shed some lights on the different dimensions of a good MVP for machine learning products drawing in the experiences that I’ve gained so far.
What is a MVP?
At Pivotal Labs, I was exposed with the lean startup thinking popularized by Eric Ries. Lean startup is basically the state-of-the art methodology for product development nowadays. Its central idea is that by building products or services iteratively by constantly integrating customer feedback you can reduce the risk that the product/service will fail (build-measure-learn).
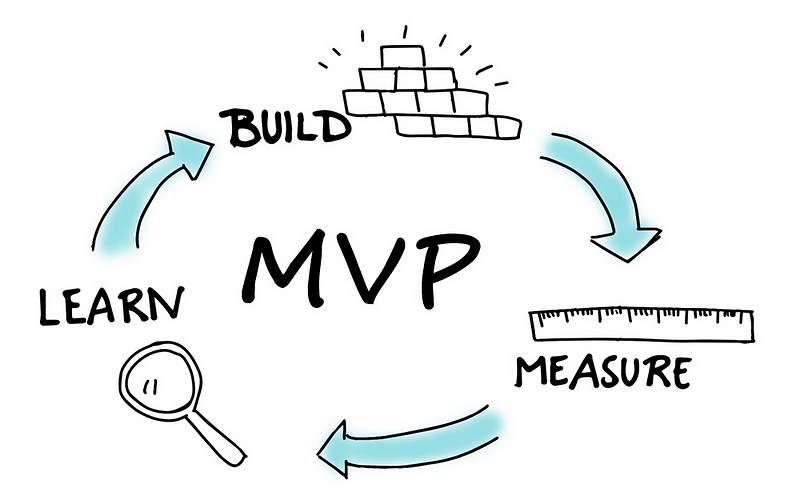
An integral part of the build-measure-learn concept is the MVP which is essentially a “version of a new product which allows a team to collect the maximum amount of validated learning about customers with the least effort”. One well known example is to validate whether mobility will be successful or not (see image below).
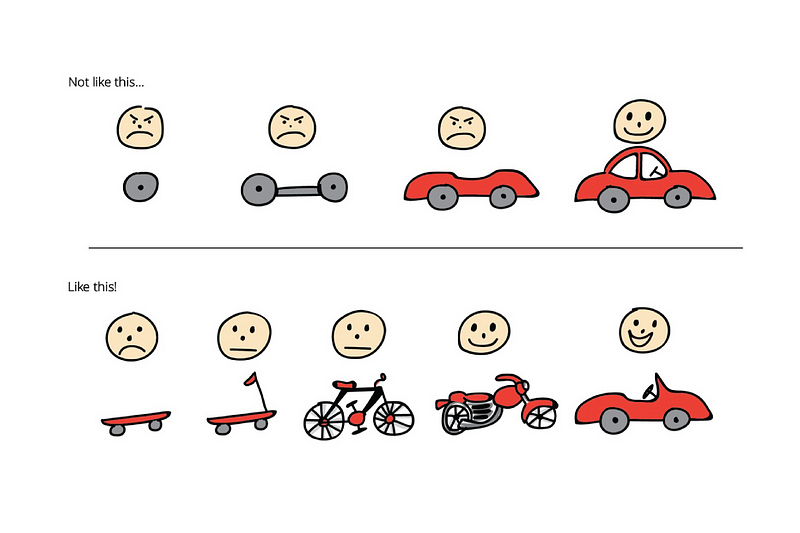
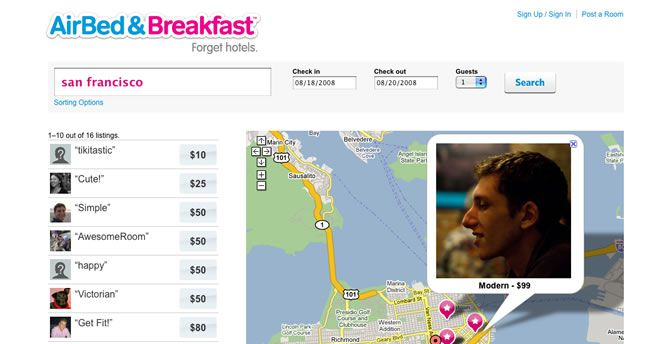
We essentially start with the smallest effort to test the idea. In this case, we just take two wheels and a board. Then we ship this to the market and get feedback to continuously improve our product by adding more complexity to it. In this case we ended up with a car that integrates the consumer’s feedback. A well known example is Airbnb. In 2007, Brian Chesky and Joe Gebbia wanted to start their own business but also couldn’t afford the rent in San Francisco. At the same time, there was a design conference coming to town. They decided to rent out their place to conference attendees who didn’t find a hotel nearby. What they did was to take pictures of their apartment, put it online on a simple website (see image below) and soon they had three paying guest for the duration of the conference. This little test gave them valuable insights that people would be willing to pay to stay in someone else’s home rather than a hotel and that not just recent college grads would sign up. Afterwards they started Airbnb and the rest is history (if you want to read more successful MVP stories check out this link).
In contrast to this, the other approach is by constructing the car one by one from the wheels up to the chassis without ever shipping it once. However, this approach is very costly. At the end of the day, we might ship a product that a customer doesn’t want. For example, let’s take Juicero as an example. They raised $120m from investors to create a well designed juice-squeezing machine which they released after some time of development for a very high price (initially it was originally priced at $699 and then subsequently reduced to $399). Along with the machine, you could also buy juice packs filled with raw fruits and vegetables priced at $5–7. Maybe some of you might know but the company already shutdown because it didn’t realize that you didn’t really need a high-priced juice-squeezing machine to squeeze out the juice packs. They didn’t really understand their customers. A simple user research would have made them aware that you don’t need an expensive machine to squeeze out the juice packs but two healthy hands would haven been enough.

How does the MVP concept relate to machine learning products?
The MVP concept can also be applied to machine learning because at the end of the day, machine learning is also part of the overall product or the end product itself. In terms of this, there are three important dimensions that I consider as important:
- Minimum Viable Model
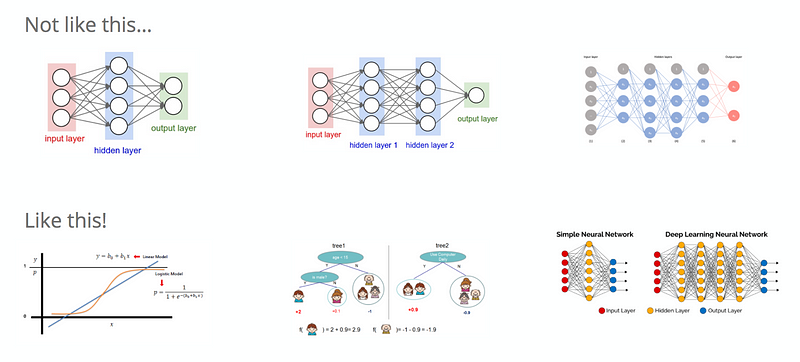
One important part of the ML product is the modelling exercise itself. Let’s assume we have a classification problem where we want to classify some data into pre-defined categories such as hotdog vs. not hotdog!

A possible approach to solve this classification problem would be to take a neural network with one hidden layer. We would next train and evaluate the model. Then depending on the results, we might want to keep improving our model. We then would add another hidden layer and then do the same modelling exercise again. Then depending on the results again we might add more and more hidden layers. This approach is fairly straight-forward and actually the best solution to solve the hotdog vs. no hotdog problem because no feature engineering is needed (we essentially can take the original image as input data). However, for most of the classification problems out there, unless they are not specialized problems like the ones that we face in computer vision or natural language understanding, this is not the best way to solve this kind of problem. The major drawback of deep learning is generally its interpretability. It’s generally hard to interpret the results of a neural network depending on what kind of network you use. Moreover, you fairly spend a huge amount of time in tuning the parameters of a neural network where the gain in model performance is negligible.
Start simple and establish a baseline…
A more reasonable approach for most of the classification problems is rather to start with a linear model like logistic regression. Although in many real-world applications the assumption of linearity is unrealistic, logistic regression does fairly well and serves as a good benchmark aka baseline model. Its main advantages are also interpretability and you get the conditional probabilities for free which is very convenient in many cases.
Then to improve the model and also to relax the linearity assumption, you could use tree-based models. In this case, there are two broad categories, bagging and boosting. Under the hood, both use decisions trees but with a different way of training it. Finally, when all options are exhausted and you would like to keep improving your model, we could then utilize deep learning techniques.
- Minimum Viable Platform

During my time at Pivotal Labs, I worked on a lot of projects to help Fortune 500 companies to help them getting started on their data journey. One of the common thing they share is that a lot of those projects started with a huge investment into their infrastructure. They spend a lot of money on buying big data platforms, the so called “data lakes”. Then after buying them, they started to load the data into their data lakes without even thinking of potential use cases. Then they heard about something called Apache Spark and added this to the layer as well. Now since AI has been the next big thing, they’ve also started to purchase GPUs and put deep learning frameworks such as TensorFlow on top of this. Sounds great right to have all (cool) tools at one place? The biggest problem, however, was that after putting all the data into their data lake, the data was just not right for the use case. They either didn’t collect the right data or it didn’t just exist that can support the potential use case.
Use the cloud to bootstrap your “data” initiatives…
A more reasonable approach would be not to think of hardware/software but more of solving the problem first. With this approach they can realize early on what data is needed in order to solve the problem and can also counteract against any data error. Other than that, there are a lot of machine learning problems, which I’ve seen so far, that can still realistically be solved on a local machine. They don’t really need to do this huge investment into their infrastructure. And in case, if data is really big, they could use cloud providers like AWS or Google Cloud where they can spin up a Spark cluster very easily. And if they have a deep learning problem, there would be many options as well. Either they can use the already mentioned cloud providers or services like FloydHub which offers them a Platform-as-a-Service (PaaS) for training and deployment of deep learning models on the cloud.
- Minimum Viable (Data) Product
The last point I want to talk about is the data product itself. Essentially, there are many examples for data products such as chatbots, spam detectors and many others — the list is long (check out Neal Lathia’s excellent article for more ML product examples). But in this case, I will focus on recommendation services as I work in the e-commerce domain now.
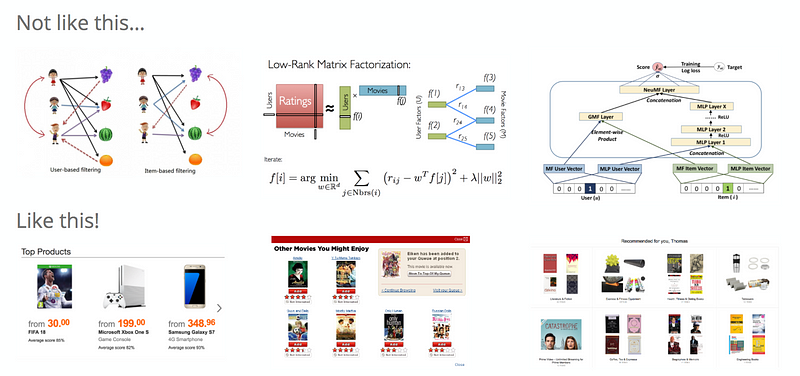
One way to start with setting up a recommendation service is to use simple similarity algorithms and then continue with matrix factorization techniques. Finally, we could also try more complex models involving deep learning methods (e.g. deep structured semantic model). However, this approach is not really recommended. Recommendations can take many forms. Recommendations, for example, given by your friends are also recommendations or the top 100 most liked products are also recommendations. Not every sophisticated algorithm that we use will also lead to success but it has to be tested. In fact, don’t be afraid to start your recommendation service without machine learning.
Do the right thing…

So the right approach would be first to set up the A/B testing framework and evaluation metrics (e.g. bounce rate or click rate) and then start with a simple approach like top products. Then after testing that users are really inclined to click on those recommendations (sometimes they have to get used to this first especially if it’s a new product feature) and eventually also might buy those recommended items, we could try it out with more sophisticated approaches like collaborative filtering techniques. For example, we could create a recommendation based on users who bought this item are also interested in those items or users who viewed this item are also interested in those items. The variety of options are endless for “users who … this item are also interested in those items”.
Summary
In this article, I gave my personal view on what MVP means for machine learning products. In essence, it is just about starting small and then iterate. Moreover to give a clearer understanding of what I mean with MVP for machine learning products, I discussed three major dimensions that I find critical for a good MVP data product:
- a minimum viable model,
- a minimum viable platform,
- and a minimum viable (data) product.
Hopefully, in your next machine learning project you will keep those three dimensions in mind as well. If you found this article useful, share it with your friends. Follow me on Medium (Dat Tran) or on Twitter (@datitran) to stay up-to-date with my work. Thanks for reading!
Original. Reposted with permission.
Related: