Natural Language Processing Nuggets: Getting Started with NLP
Check out this collection of NLP resources for beginners, starting from zero and slowly progressing to the point that readers should have an idea of where to go next.
This is a collection of some of my natural language processing (NLP) posts from the past year or so. They start from zero and progress accordingly, and are suitable for individuals looking to creep toward NLP and pick up some of the basic ideas, before hopefully branching out further (see the final 2 resources listed below for more on that).
Not originally intended to be in any particular order, if you are inclined to read them all, they are best approached in the order they are presented.
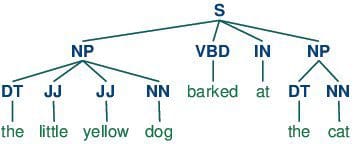
Natural Language Processing Key Terms, Explained
At the intersection of computational linguistics and artificial intelligence is where we find natural language processing. Very broadly, natural language processing (NLP) is a discipline which is interested in how human languages, and, to some extent, the humans who speak them, interact with technology. NLP is an interdisciplinary topic which has historically been the equal domain of artificial intelligence researchers and linguistics alike; perhaps obviously, those approaching the discipline from the linguistics side must get up to speed on technology, while those entering the discipline from the technology realm need to learn the linguistic concepts.
It is this second group that this post aims to serve at an introductory level, as we take a no-nonsense approach to defining some key NLP terminology. While you certainly won't be a linguistic expert after reading this, we hope that you are better able to understand some of the NLP-related discourse, and gain perspective as to how to proceed with learning more on the topics herein.
So here they are, 18 select natural language processing terms, concisely defined, with links to further reading where appropriate.
A Framework for Approaching Textual Data Science Tasks
Natural language processing (NLP) concerns itself with the interaction between natural human languages and computing devices. NLP is a major aspect of computational linguistics, and also falls within the realms of computer science and artificial intelligence.
Text mining exists in a similar realm as NLP, in that it is concerned with identifying interesting, non-trivial patterns in textual data.
OK, great. But really, what is the difference?
First off, the exact boundaries of these 2 concepts are not well-defined and agreed-upon (see data mining vs. data science), and bleed into one another to varying degrees, depending on the practitioners and researchers with whom you discuss such matters. I find it easiest to differentiate by degree of insight. If raw text is data, then text mining is information and NLP is knowledge (see the Pyramid of Understanding below). Syntax versus semantics, if you will.
A General Approach to Preprocessing Text Data
Recently we looked at a framework for approaching textual data science tasks. We kept said framework sufficiently general such that it could be useful and applicable to any text mining and/or natural language processing task.
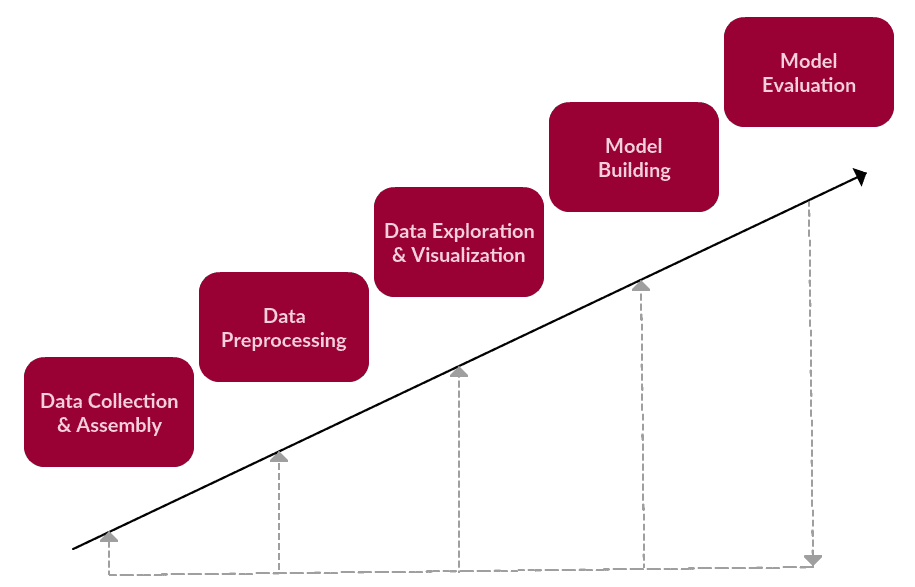
The high-level steps for the framework were as follows:
- Data Collection or Assembly
- Data Preprocessing
- Data Exploration & Visualization
- Model Building
- Model Evaluation
Though such a framework would, by nature, be iterative, we originally demonstrated it visually as a rather linear process. This update should put its true nature in perspective (with an obvious nod to the KDD Process):
Building a Wikipedia Text Corpus for Natural Language Processing
One of the first things required for natural language processing (NLP) tasks is a corpus. In linguistics and NLP, corpus (literally Latin for body) refers to a collection of texts. Such collections may be formed of a single language of texts, or can span multiple languages -- there are numerous reasons for which multilingual corpora (the plural of corpus) may be useful. Corpora may also consist of themed texts (historical, Biblical, etc.). Corpora are generally solely used for statistical linguistic analysis and hypothesis testing.
The good thing is that the internet is filled with text, and in many cases this text is collected and well oganized, even if it requires some finessing into a more usable, precisely-defined format. Wikipedia, in particular, is a rich source of well-organized textual data. It's also a vast collection of knowledge, and the unhampered mind can dream up all sorts of uses for just such a body of text.
What we will do here is build a corpus from the set of English Wikipedia articles, which is freely and conveniently available online.
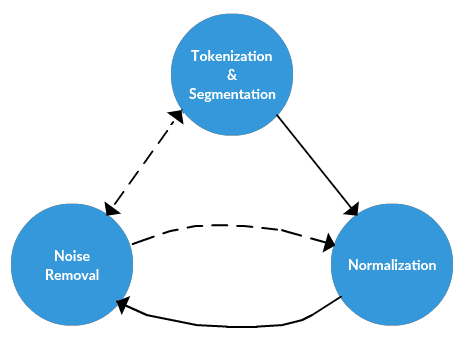
Text Data Preprocessing: A Walkthrough in Python
n a pair of previous posts, we first discussed a framework for approaching textual data science tasks, and followed that up with a discussion on a general approach to preprocessing text data. This post will serve as a practical walkthrough of a text data preprocessing task using some common Python tools.
Our goal is to go from what we will describe as a chunk of text (not to be confused with text chunking), a lengthy, unprocessed single string, and end up with a list (or several lists) of cleaned tokens that would be useful for further text mining and/or natural language processing tasks.
Getting Started with spaCy for Natural Language Processing
While NLTK is a great natural language... well, toolkit (hence the name), it is not optimized for building production systems. This may or may not be of consequence if using NLTK only to preprocess your data, but if you are planning an end-to-end NLP solution and are selecting an appropriate tool to build said system, it may make sense to preprocess your data with the same.
While NLTK was built with learning NLP in mind, spaCy is specifically designed with the goal of being a useful library for implementing production-ready systems.
spaCy is designed to help you do real work — to build real products, or gather real insights. The library respects your time, and tries to avoid wasting it. It's easy to install, and its API is simple and productive. We like to think of spaCy as the Ruby on Rails of Natural Language Processing.
spaCy is opinionated, in that it does not allow for as much mixing and matching of what could be considered NLP pipeline modules, the argument being that particular lemmatizers, for example, are not optimized to play well with particular tokenizers. While the tradeoff is less flexibility in some aspects of your NLP pipeline, the result should be increased performance.
5 Free Resources for Getting Started with Deep Learning for Natural Language Processing
Interested in applying deep learning to natural language processing (NLP)? Don't know where or how to start learning?
This is a collection of 5 resources for the uninitiated, which should open eyes to what is possible and the current state of the art at the intersection of NLP and deep learning. It should also provide some idea of where to go next. Hopefully this collection is of some use to you.
5 Fantastic Practical Natural Language Processing Resources
Are you interested in some practical natural language processing resources?
There are so many NLP resources available online, especially those relying on deep learning approaches, that sifting through to find the quality can be quite a task. There are some well-known, top notch mainstay resources of mainly theoretical depth, especially the Stanford and Oxford NLP with deep learning courses:
- Natural Language Processing with Deep Learning (Stanford)
- Deep Learning for Natural Language Processing (Oxford)
But what if you've completed these, have already gained a foundation in NLP and want to move to some practical resources, or simply have an interest in other approaches, which may not necessarily be dependent on neural networks? This post (hopefully) will be helpful.
Related:
- On the contribution of neural networks and word embeddings in Natural Language Processing
- NLP in Online Courses: an Overview
- Implementing Deep Learning Methods and Feature Engineering for Text Data: FastText